任务B-数据分析与可视化 解析
子任务一: 数据分析
1.分别统计各类型的电影总数,展示前五名
import pandas as pd
df = pd.read_csv("movie.csv")
df.drop_duplicates("标题", ignore_index=True, inplace=True) # 删除重复标题
dfdrop_duplicates用来删除重复标题 给他穿个inplace表示在原数据上进行修改
movietypeSum = df['类型'].apply(lambda x:str(x).split(" / "))
movietypeSum = movietypeSum.explode("类型")
movietypeSum = movietypeSum.value_counts()
movietypeSum.head()apply函数 将类型这一列分割
explode 将分割完的列表 惊醒拆分 拆分成单独的一列
2、 统计各导演的电影的平均评分排名,展示前五名
movieMeanMovie = df.loc[:,['导演', "评分"]]
movieMeanMovie['导演'] = movieMeanMovie['导演'].apply(lambda x:str(x).split(", "))
movieMeanMovie = movieMeanMovie.explode("导演", ignore_index=True)
movieMeanMovie = movieMeanMovie.groupby("导演").agg({"评分":'mean'}).sort_values(by='评分', ascending=False)
movieMeanMovie.head()发现一行中导演可以有时有很多个
还是老样子进行分隔
然后进行分组 聚合 算出各导演的评分平均分 然后进行降序排序
3. 统计2012年电影的平均评分保留两位小数
df['发行年份'] = df['发行年份'].str.extract(r'(\d{4})')
movieScore = df.loc[df['发行年份'] == '2012']
yearMean = float(movieScore['评分'].mean())
round(yearMean, 2)pandas中的字符串方法 中有一个extract 可以用正则提取数据
写正则 提取前四个数字
然后 按条件提取 发行年份 求平均值 后保留小数即可
4、 统计所有评分大于等于8.5的电影的平均时长,取整
movieDuration = df.loc[df['评分'] > 8.5]
movieDuration.drop(movieDuration[movieDuration['时长'] == 0].index)
round(float(movieDuration['时长'].mean()))按条件提取
drop函数中需要注意 是先条件提取出时长为0的 然后获取这些为0的索引 然后删除
子任务二:数据可视化
import matplotlib.pyplot as plt
import seaborn as sns
scoreMoveSum = df['评分'].value_counts()
scoreMoveSum = pd.DataFrame({"评分":scoreMoveSum.index, "数量": scoreMoveSum.values})
plt.figure(figsize=(10,6))
sns.set(font='SimHei')
sns.barplot(data=scoreMoveSum.head(5), x='评分', y='数量')
plt.xlabel("评分")
plt.ylabel("数量")
plt.xticks(rotation=45) # 将文字 倾斜45度
plt.show()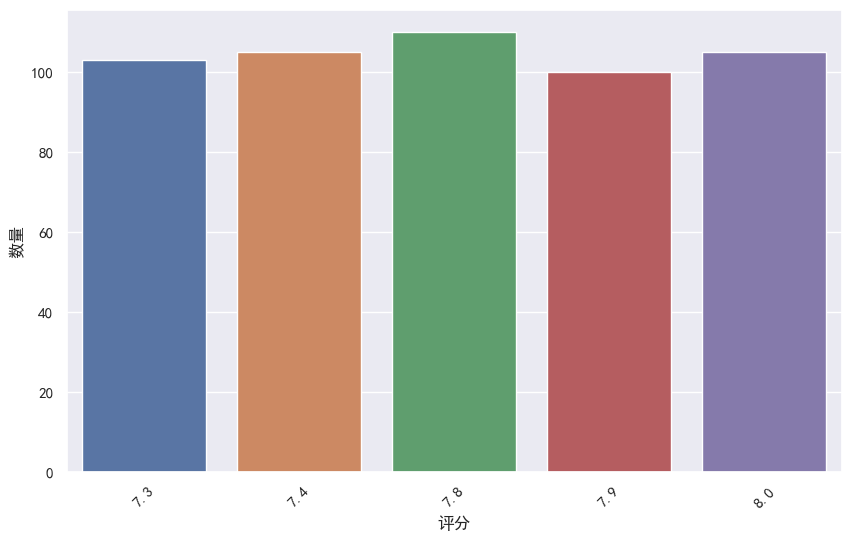
2、 用折线图显示2000年以后的电影平均评分走势
movieYear2000 = df.loc[df['发行年份'] >= '2000']
movieYear2000 = movieYear2000.groupby("发行年份").agg({"评分": 'mean'})
plt.figure(figsize=(10,6))
sns.set(font='SimHei')
sns.lineplot(data=movieYear2000, x='发行年份', y='评分', marker='o')
plt.xlabel("发行年份")
plt.ylabel("评分")
plt.xticks(rotation=45)
plt.show()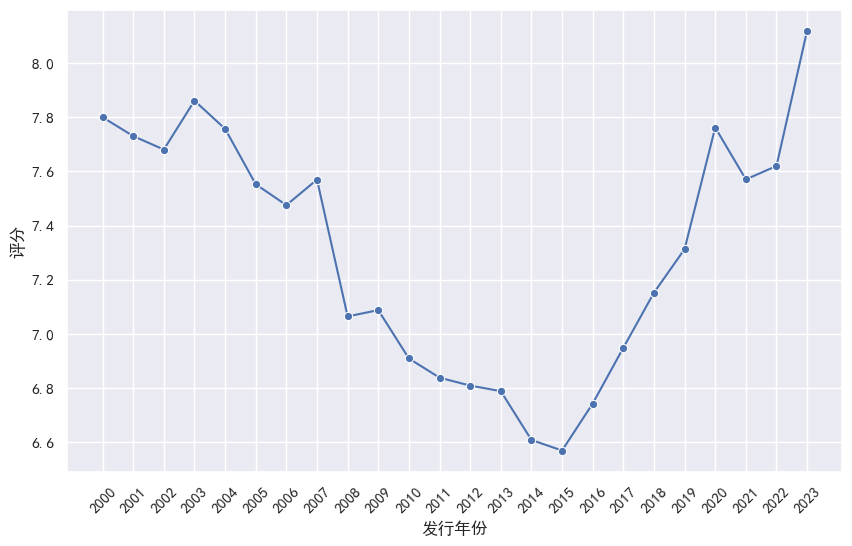
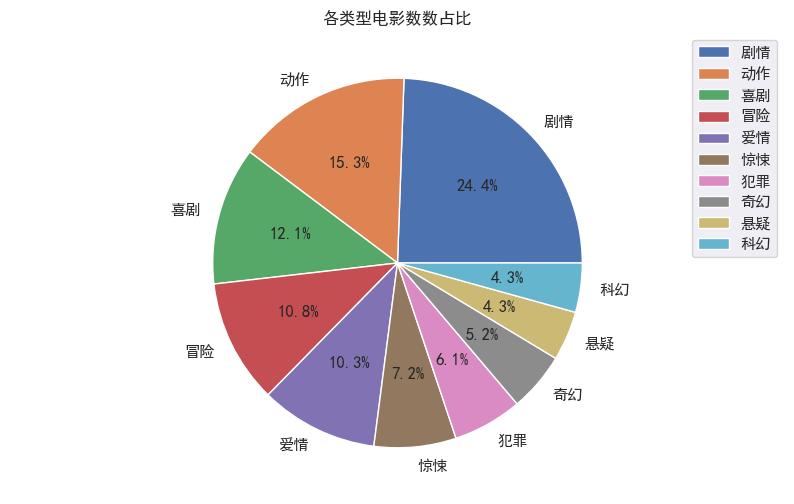
3、 用饼图显示各类型电影数数占比
tmpMovie = movietypeSum.head(10)
plt.figure(figsize=(10,6))
plt.rcParams['font.sans-serif']=['SimHei']
labels = tmpMovie.index
sizes = tmpMovie.values
plt.axis("equal")
plt.pie(sizes, labels=labels, autopct="%.1f%%")
plt.legend(loc='best')
plt.title("各类型电影数数占比")
plt.show()